
2025.02.03 - [팀 프로젝트/플러스 프로젝트] - 성능 개선 2편: Index 설계하기 (with Explain analyze, Explain)
성능 개선 2편: Index 설계하기 (with Explain analyze, Explain)
인덱스 없이 조회, 얼마나 걸릴까?개선이 시급한 쿼리는 거래소/경매장 | 전체조회/인기아이템 이렇게 4개다.총 4개 쿼리의 실행속도를 우선 알아보자.hibernate 2차캐시는 사용하지 않고 있다.(defau
roqkfchqh.tistory.com
해당 글에서 이어집니다.
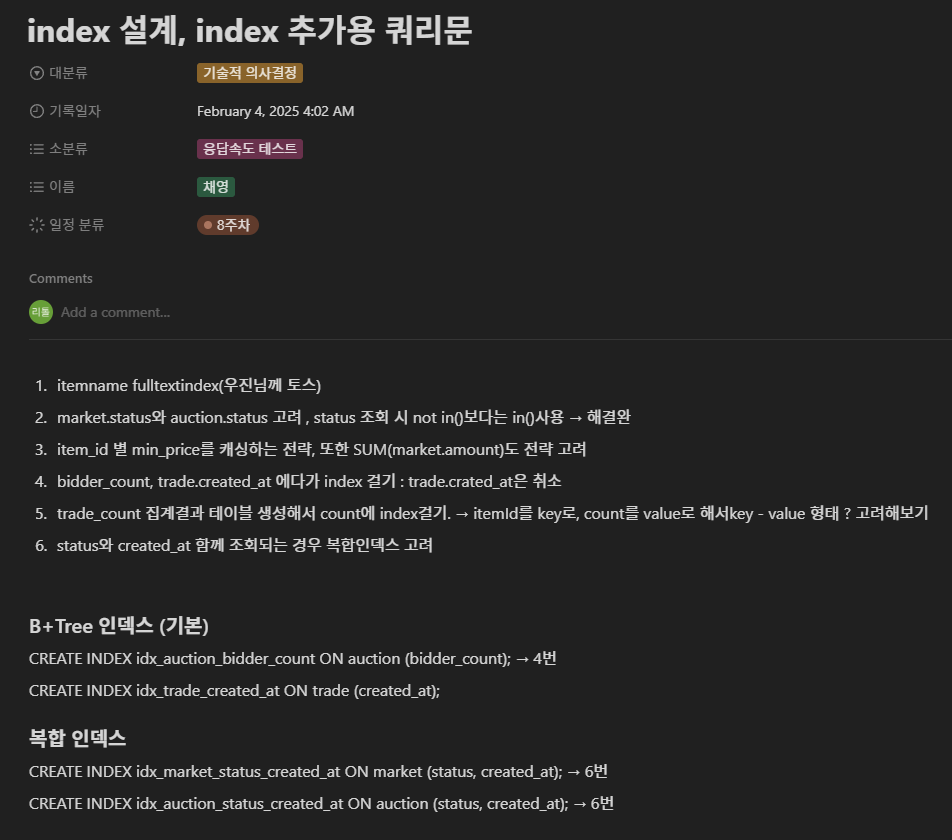
요약하면 인덱스는 총 5개를 걸고,(bidderCount, trade createdAt, market/auction status-createdAt 복합인덱스, tradeCount)
집계용 테이블(tradeCount)를 뒀다.
trade.createdAt은 결국 조회에는 쓰이지 않았지만, totalCount를 스케줄링 할때 필요해서 인덱스를 걸어놨다.
일단 2번, 4번, 5번, 6번 적용 후 결과를 보자.

결과 분석은 explain analyze로 수행한다. 전의 쿼리와 변수가 같은 개선된 쿼리를 총 4개 준비해놓았다
아래에서 이야기하는 '성능' 은 actual time 기준으로 생각한 것이고, 실제와는 괴리감이 있을 것이다.
인기 마켓 아이템 조회(이전 actual time = 137915)

기존엔 not in('completed', 'cancelled')이나 created_at같은 조건을 한꺼번에 처리하느라 테이블 전체를 죄다 뒤지며 수백만건의 loop를 돌고, 그 후에 필요한 열만 꺼내려고 조인하는 과정에서 nested loop가 엄청나게 반복되면서 비용이 폭증했었다.
-> 개선점:
not in 대신 in('on_sale')을 사용해 인덱스를 빠르게 사용할 수 있게 하고, 복합 인덱스(status, createdAt)를 태워서 필요 건수만 빠르게 가져오도록 했다. mysql 내부적으로 index range scan을 사용하여 풀 스캔 대비 훨씬 가벼워지고, nested loop join도 최소화 할 수 있었다.
인기 경매 아이템 조회(이전 actual time = 19246)

이 또한 원래 테이블을 통째로 스캔하고, 각 행마다 nested loop를 돌고, 부정 조건(not in)과 범위 필터를 인덱스 없이 사용했었다.
-> 개선점:
마찬가지로 index range scan을 잘 사용하도록 복합 인덱스를 만들었다. 결과적으로 조인 호출 횟수도 급감하고, 'temporary table with deduplication' 자체 cost도 60만대에서 2-30만대로 줄일 수 있었다.
전체 마켓 아이템 조회(이전 actual time = 24637)

아직 itemName에 대한 full text index가 적용되어있지 않아서 인덱스를 타지 못해 유의미한 차이는 벌릴 수 없었다.
또한 min(m.price)의 최솟값을 구하고, 정렬까지 해야되는데 인덱스로 커버가 안 돼서 대책이 필요한 상황이다.
-> 개선점:
이것 역시 in('on_sale')을 사용하여 어느정도 개선은 가능했다.
전체 경매 아이템 조회(이전 actual time = 19996)
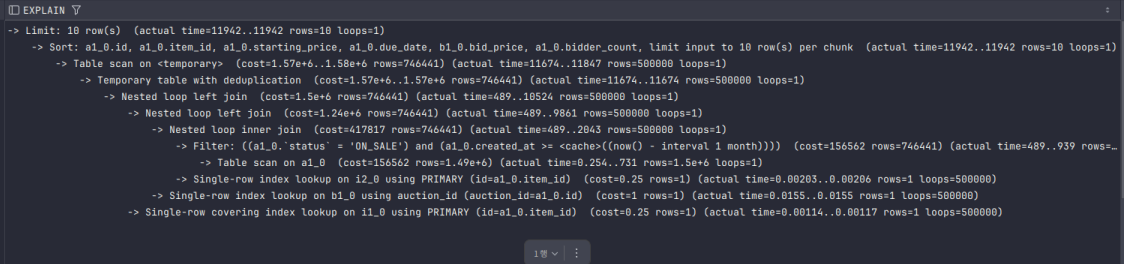
다른 것들과 마찬가지로 풀 스캔(itemname, not in, 날짜범위검색..) -> 엄청난 nested loop -> rows 폭증 상태였는데,
-> 개선점:
index range scan -> nested loop 감소 -> rows 500000만 이상에서 3000대로 감소 하였다.
동적 정렬이나 집계 로직은 구조상 완전히 없앨 수 없으나 인덱스 필터를 사용해 원본 데이터 건수를 줄이니 체감 성능이 크게 좋아졌다.
postman 실행시간 테스트

postman에서도 테스트 해보자.

거래소 인기아이템: 조회 안됨 -> 47초
경매장 인기아이템: 1분 30초 -> 41초
경매장 메인: 21초 -> 16초
거래소 메인: 36초 -> 1분 13초 (??)

....
왤까?
왜.. 인덱스를 넣었는데 더 느리니?
도무지 믿어지지 않아서 이전 버전으로 되돌리고 현재 버전과 함께 놔두고 비교를 해보자..
그리고 인덱스는 삭제하지 말자. 인덱스가 아니라 로직 문제라고 생각한다.
logging.level.org.hibernate.SQL=debug
logging.level.org.hibernate.orm.jdbc.bind=trace이번엔 확실한 디버깅을 위해 application.properties에 해당 설정을 추가했다

대충 이쯤에서 알아챈게, 원래는 쿼리dsl을 보고 대충 짠 sql문으로 explain analyze를 실행했었는데
그거랑 실제 hibernate가 보내는 쿼리랑 매우 다르다는 점을 알았다
사실 인덱스의 성능을 개선시키는 과정에서는 내가 짠 쿼리문으로도 가능했는데 디버깅은 전혀 불가능하다..교훈을 얻었다. 대충하지말자..



아무튼 이게 이전 버전



이게 성능 향?상이 들어간 버전이다.
내 나름대로 내린결론은, "인덱스가 예상대로 동작하지 않는다" 였다. 현재 status컬럼의 선택도가 너무 낮아 in을 쓰던 not in을 쓰던 풀테이블스캔을 진행하는데, 선택도가 낮을 경우 in을 사용하는 것이 더 비효율적인 게 아닐까? 공부가 필요한 항목이다
그래서 오히려 인덱스와 in(ON_SALE)을 빼고 전체 데이터를 불러오는 게 더 빠를 것 같다고 생각해서,
현재 버전에서 해당 구문을 빼고 explain을 돌려봤는데

10배 빨라짐 ㅋㅋㅋ
아 재밌당

빠세잉
결론은 status처럼 선택도가 낮은 컬럼에는 인덱스를 신중하게 걸거나 복합인덱스를 잘 활용해봐야하고,
지금 저렇게 시간이 느린 이유는 필터링 때문도있지만
1.순수하게 그냥 데이터가 많음
2.full text index 적용안됨
3.cursor pagination 적용안됨
4. 내 컴터가 구림
다음글에서 cursor pagination을 적용해보자ㅇㅅㅇ
'팀 프로젝트 > market.normalization.project' 카테고리의 다른 글
| 성능 개선 4편 & 트러블슈팅: 커서 기반 페이지네이션 + 전략 패턴 (1) | 2025.02.05 |
|---|---|
| 성능 개선 2편: Index 설계하기 (with Explain analyze, Explain) (0) | 2025.02.04 |
| 성능 개선 1편: db조회 성능 개선 플랜 수립 (0) | 2025.02.03 |



