
목표
거래소와 경매장의 인기 아이템 조회는 상당히 많이 일어나기에 caching이 필수적이라고 생각한다.
인기아이템 뿐만아니라, 경매장에서
1. "마감 시간이 임박한 경매 목록"
2. "현재 입찰가가 가장 높은 항목"
에 대해서도 조회가 굉장히 많이 일어난다.
하지만 해당 캐싱 전략을 수립하거나 멀티인스턴스에서 접근하기 전에
우선 인덱스 등을 이용하여 순수 조회 성능부터 개선해야 한다.
따라서,
1. 인덱스를 통한 db 조회성능 개선
2. 커서 기반 페이지네이션 적용
3. 풀텍스트 인덱스 적용
3. DB vs Redis
순으로 진행한다.
테스트 조건, 환경 수립
제일 정하기 어렵다. 실제 게임이라고 생각해보면, 과연 얼마나 있을까.. 하던 게임에서 한번 찾아보자.

원정대(계정) 65만개
아이템 개수 1315 x 10 = 13150개

경매장에서 최근 거래는 한달간 저장하는 것 같고, 1월 3일에 2시간동안 1만건의 거래가 발생했으니 하루에 12만건의 거래가 발생한다 치고 한달이면 360만건이다.
거래소를 합하면(아무래도 거래소가 거래량이 압도적이다.) 더 많을거다
비슷한 조건으로 한번 시도해보자.
user : 40만명
item : 1만개
market : 300만개
trade : 600만개
auction : 150만개
bid : 300만개

아 물론 하다가 놑트북 터질 것 같으면 줄일거임 ㅋ
DB에 대량의 더미데이터 집어넣기
batch insert로 진행하다가 배치사이즈를 5천에서 1천으로 줄여도 보고,
@Async로 비동기 처리도 해봤는데 스레드가 부족하여서 계속 실패했다.
원인은 batch insert에 사용되는 jpa persist()가 삽입에 취약하다고 한다.
방법을 찾다가, 대용량 데이터를 한꺼번에 삽입할 때 csv가 좋다고 하여서 시도해보았다.
private static void generateBidsCSV() throws IOException {
FileWriter writer = new FileWriter("bids.csv");
writer.append("id,user_id,auction_id,bidPrice,updatedAt\n");
Set<Integer> usedAuctionIds = new HashSet<>();
for (int i = 1; i <= BID_COUNT; i++) {
int auctionId;
do {
auctionId = random.nextInt(AUCTION_COUNT) + 1;
} while (!usedAuctionIds.add(auctionId));
writer.append(String.valueOf(i)).append(",")
.append(String.valueOf(random.nextInt(USER_COUNT) + 1)).append(",")
.append(String.valueOf(auctionId)).append(",")
.append(String.valueOf(random.nextLong(1_000_000))).append(",2025-01-31\n");
}
writer.flush();
writer.close();
}이런 코드를 짜고(ai한테 짜달라고 하고) 실행시켜서 csv파일로 만들고

해당 csv파일을 sql문 안에다 넣어서 실행시키기만 하면 db에 데이터가 자동으로 삽입된다.
정확히는 mysql의 LOAD DATA INFILE라는 기능을 사용하는거다
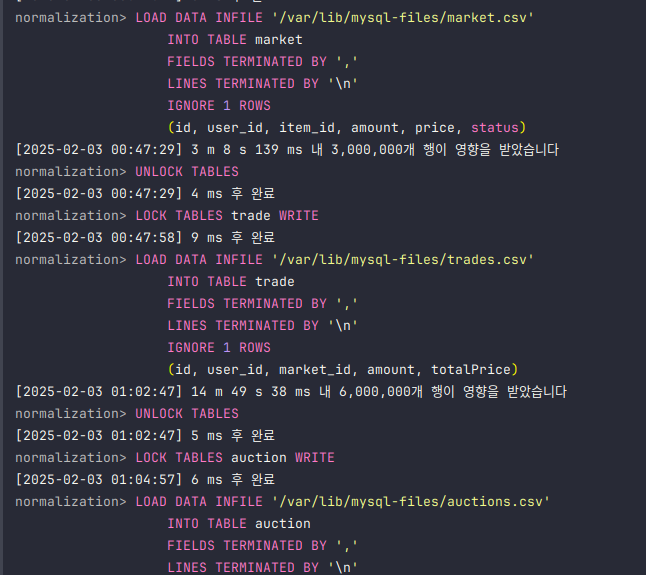
주의사항이 있는데 대용량 데이터일 경우에는 LOCK TABLES를 무조건 걸어줘야한다.
LOCK TABLES를 LOAD DATA INFILE과 함께 사용하면 mysql이 내부적으로 index를 임시로 비활성화하고, 데이터 삽입 후 다시 활성화해 성능을 최적화한다.
index는 삽입 시에 약간의 오버헤드가 발생하니 확실히 대용량데이터를 한번에 넣을 경우엔 부담이 크다.
또한 여러 트랜잭션이 동시에 동일한 테이블에 접근하는 상태도 방지할 수 있다(race condition)
안정적으로 엄청난 양의 데이터를 삽입할 수 있었다.
이제 여기다 인덱스도 넣고.. 본격적으로 성능 개선을 시작해보자
'팀 프로젝트 > 플러스 프로젝트' 카테고리의 다른 글
| 성능 개선 3편: Index 적용하고 비교분석하기 (0) | 2025.02.04 |
|---|---|
| 성능 개선 2편: Index 설계하기 (with Explain analyze, Explain) (0) | 2025.02.04 |
| 트러블슈팅: queryDSL 중복집계, 비정상적으로 큰 count 문제(with only_full_group_by) (0) | 2025.02.02 |



