
커버링 인덱스란?
커버링 인덱스는 쿼리에서 필요로 하는 모든 컬럼을 포함하는 인덱스다.
쿼리가 요청하는 모든 데이터가 인덱스 자체에 이미 포함되어 있어, 데이터베이스가 원본 테이블에 접근할 필요 없이 인덱스만으로 쿼리를 처리할 수 있다.
MySQL에서 커버링 인덱스는 select절에 있는 모든 컬럼과 where, order by, group by절에서 사용되는 모든 컬럼이 인덱스에 포함되어야 한다.
이 때문에 쓰기 작업에서 트레이드오프가 존재하지만, 일반적인 웹 서버에서 읽기:쓰기 비율이 9:1정도인 것을 감안하면 오프셋 기반 페이지네이션에서는 커버링 인덱스를 적극적으로 활용하는 편이 좋다고 생각한다. 또한 유지 보수도 조금 까다로운 편이다. select절이 바뀌면 인덱스를 재설정해주어야 한다.
커버링 인덱스는 보통 복합 인덱스를 사용하므로 순서가 중요하다. "가장 많이 사용되는 디폴트 값" 일수록 왼쪽에 둬야 한다.
커버링 인덱스의 동작
커버링 인덱스가 select절의 모든 컬럼을 포함해야 하는 이유를 알아보자.
SELECT name FROM users WHERE email = 'a@a.com';
우선, 일반적인 clustered index와 secondary index의 동작을 다시 한번 파악할 필요가 있다.
인덱스가 create index idx_email on users(email); 이렇게 잡혀있는 상황이라고 생각해보자.
위의 쿼리에서 name이 필요하니까
1. idx_email에서 email='a@a.com'인 row를 찾고
2. 해당 row의 pk값을 따라가서
3. clustered index에서 name값을 읽게된다.
이 때는, secondary index 에서 clustered index(원본 데이터)로 접근하게 된다
이제 커버링 인덱스의 경우를 살펴보자. 같은 쿼리를 조회한다고 가정했을 때 커버링 인덱스는
create index idx_email_name on users(email, name); 이고
이제 email, name 둘 다 인덱스에 포함돼 있으니까
1. idx_email_name에서 바로 값을 찾고
2. clustered index를 따라가 테이블에 접근할 필요가 없다.
즉, 인덱스 리프 노드만 보고 끝나게 되므로 I/O가 최소화되는 방식이다.
정리하자면, '모든 조회를 인덱스에서만 처리하게 되므로' 노드에 모든 select 컬럼을 포함해야 한다. 따라서 선택과 집중이 중요하다
1. 조회 할 컬럼 개수만큼 인덱스에 들어가야 하므로, 개수가 증가할 수록 인덱스 크기도 폭증하기 때문에 관리가 어렵다
2. 쓰기 비용도 그만큼 증가하게 된다
3. select컬럼이 바뀌면 인덱스가 무용지물이 되므로 꾸준한 관리가 필요하다
-> 쿼리 로그를 꾸준히 분석해서 사용량이 높은 쿼리만 최적화하고, explain에서 Using index가 뜨는지 항상 확인해줘야한다.(Using index는 커버링 인덱스를 사용하고 있다는 지표다)
커버링 인덱스 적용
본격적으로 쿼리들의 조회 성능을 향상시켜보자.

현재 전체 거래소 조회 쿼리이다. 이 쿼리의 커버링 인덱스는 다음과 같다
CREATE INDEX idx_market_all_covering
ON market (status DESC, item_id DESC, amount DESC, price DESC);market에 status, item_id, amount, price를 내림차순으로 걸어주면 된다.
내림차순인 이유는, 우리 서비스에서 default 정렬은 desc이기 때문이다. 방향을 맞춰주면 좋다




인덱스 적용 전에는 필요없는 데이터를 66%나 불러왔는데, 적용 후 필요한 데이터들만 불러온 것을 볼 수 있다.
Using where; Using index; 로 커버링 인덱스가 정상적으로 적용되었다
참고로 item테이블의 name에도 인덱스를 걸어주면 완벽히 커버링 인덱스를 사용한 것이 되지만, 조회 성능에 도움되진 않는다.
우리 서비스에서 item테이블은 id, name컬럼으로만 이루어져있기 때문에 풀테이블스캔과 인덱스 풀스캔에 성능차이가 없다.
나중에 name에 full text index를 거는 것만 고려를 해야 될 거다.
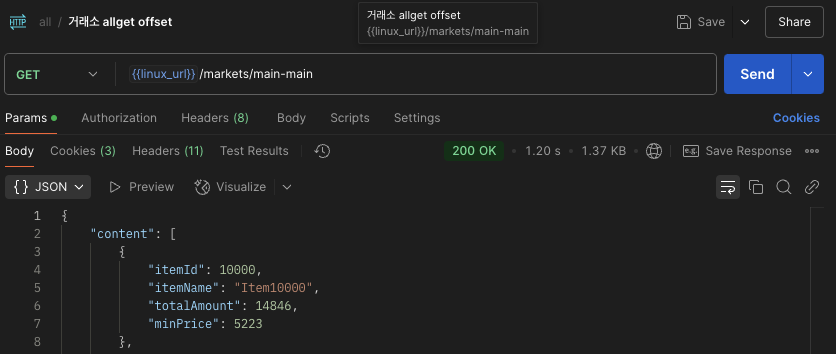
포스트맨 조회 성능 또한 3.03s -> 1.20s 로 2.5배 향상되었다.
하지만 여전히 1초 이상으로, 그다지 향상된 모습은 아니다. 왜일까? 그 이유는 서브쿼리에서 찾을 수 있었다.
커버링 인덱스와 서브쿼리
복잡한 SQL문에선 커버링 인덱스를 사용할 때 서브쿼리를 사용해야 한다. 인덱스만으로 정렬, 페이징을 먼저 수행하고 나서 실제 필요한 데이터만 테이블에서 조회하기 위함이다.
커버링 인덱스는 쿼리에서 사용하는 모든 컬럼이 인덱스에 포함되어 있을 때만 동작한다.
하지만 일반적인 쿼리에서는 select절에서 join된 여러 컬럼들도 함께 조회하게 되는데, 이 join된 테이블의 컬럼들이 인덱스에 포함되어 있지 않으면 결국 mysql은 인덱스를 통해 조건에 맞는 pk만 찾고, 다시 원본 테이블로 접근해서 나머지 데이터를 조회한다.
이 경우 테이블 접근 비용이 발생하므로 커버링 인덱스가 가진 장점인 디스크 I/O 최소화 효과를 얻을 수 없다.
반면, 서브쿼리를 활용하면 인덱스에 존재하는 컬럼만으로 선택적으로 조회할 수 있다.
예를 들어 id와 정렬 기준 컬럼만 인덱스에 있고 이를 서브쿼리에서 사용하면, 인덱스만으로 정렬과 페이징이 끝나게 되어 커버링 인덱스로 완전하게 처리된다.
그 이후 join으로 본문 데이터를 조회하면 필요한 row만 빠르게 접근할 수 있어 전체 정렬이나 full scan 비용을 피할 수 있다.
따라서 커버링 인덱스의 이점을 실질적으로 살리려면 서브쿼리로 인덱스 대상 컬럼만 선제 처리 해주는 방식을 사용해야 한다.
다만 jpql, querydsl에선 from절에 서브쿼리를 지원해주지 않아서 cluster key를 커버링 인덱스로 조회하고 해당 key들로 select문의 컬럼들을 조회하는 방식을 사용해야 한다.
@Override
public Page<MarketListResponseDto> findAllMarketItems(
String searchKeyword,
String sortBy,
String sortDirection,
Pageable pageable
) {
QMarket market = QMarket.market;
QItem item = QItem.item;
BooleanBuilder builder = new BooleanBuilder();
if (searchKeyword != null && !searchKeyword.isBlank()) {
builder.and(item.name.containsIgnoreCase(searchKeyword));
}
builder
.and(market.status.eq(Status.ON_SALE));
JPQLQuery<MarketListResponseDto> query = queryFactory
.select(new QMarketListResponseDto(
item.id,
item.name,
market.amount.sum().coalesce(0),
market.price.min().coalesce(0L)
))
.from(market)
.join(market.item, item)
.where(builder)
.groupBy(item.id, item.name)
.orderBy(determineSorting(sortBy, sortDirection))
.offset(pageable.getOffset())
.limit(pageable.getPageSize());
Long count = queryFactory
.select(item.count())
.from(item)
.fetchOne();
return new PageImpl<>(query.fetch(), pageable, count == null ? 0 : count);
}현재 쿼리는 정렬, Join을 한 쿼리에서 모두 수행하기 때문에 커버링 인덱스를 잘 활용하지 못하고 있다.
그러므로 현재 쿼리도 커버링 인덱스에 최적화 된 쿼리로 서브쿼리를 사용해 pk만 우선적으로 조회하고,
실제 상세 데이터를 간단한 join으로 처리하도록 리팩토링 해보자
@Override
public Page<MarketListResponseDto> findAllMarketItems(
String searchKeyword,
String sortBy,
String sortDirection,
Pageable pageable
) {
QMarket market = QMarket.market;
QItem item = QItem.item;
BooleanBuilder builder = new BooleanBuilder();
if (searchKeyword != null && !searchKeyword.isBlank()) {
builder.and(item.name.containsIgnoreCase(searchKeyword));
}
builder.and(market.status.eq(Status.ON_SALE));
//커버링 인덱스로 item_id만 먼저 가져오기
List<Long> itemIds = queryFactory
.select(market.item.id)
.from(market)
.where(builder)
.groupBy(market.item.id)
.orderBy(determineSorting(sortBy, sortDirection))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
if (itemIds.isEmpty()) {
return Page.empty(pageable);
}
//실제 데이터 조회 (itemId 기반 join)
List<MarketListResponseDto> content = queryFactory
.select(new QMarketListResponseDto(
item.id,
item.name,
market.amount.sum().coalesce(0),
market.price.min().coalesce(0L)
))
.from(market)
.join(market.item, item)
.where(
market.status.eq(Status.ON_SALE),
item.id.in(itemIds)
)
.groupBy(item.id, item.name)
.orderBy(orderByField(itemIds)) //id 정렬 순서 유지
.fetch();
return new PageImpl<>(content, pageable, itemIds.size());
}
private OrderSpecifier<?> orderByField(List<Long> ids) {
String template = "FIELD({0}, " + ids.stream().map(String::valueOf).collect(Collectors.joining(", ")) + ")";
return Expressions.numberTemplate(Integer.class, template, QItem.item.id).asc();
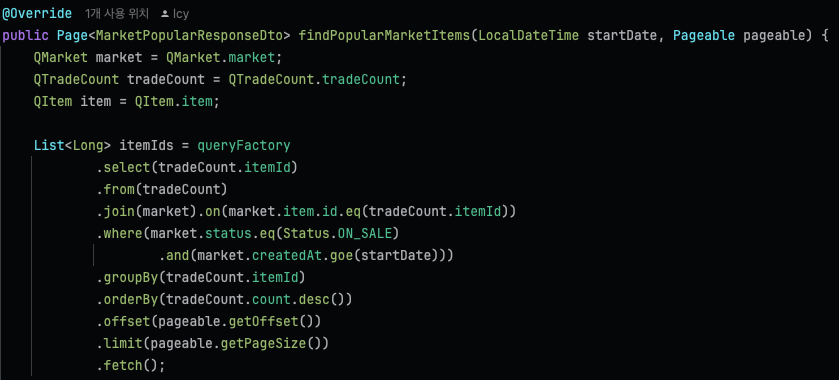
}커버링 인덱스를 사용해 itemId(pk)만 먼저 가져온 뒤, itemId 기반으로 join해 실제 데이터를 가져오도록 리팩토링하였다.
orderByField 메서드로 서브쿼리의 정렬순서를 메인쿼리에서도 유지하도록 구현했다.
메인쿼리에서 정렬순서가 유지된 채로, 해당 pk에 맞는 정보들만 join해서 가져오는 것을 확인할 수 있으며
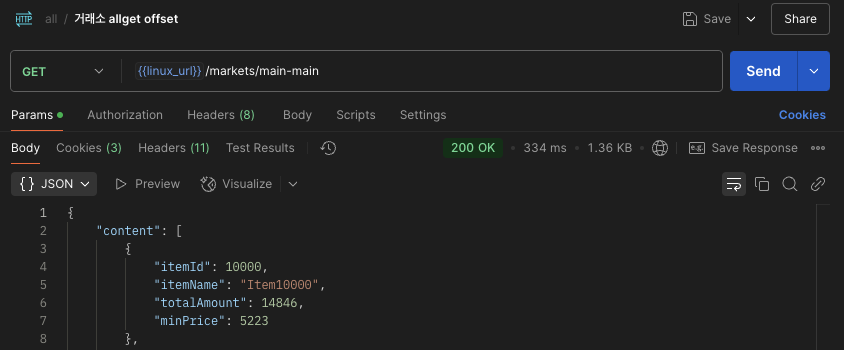
조회 속도도 커버링 인덱스 적용 전과 비교해서 3.03s -> 334ms 9배 향상되었다!
나머지 쿼리들에도 적용해주자 ~.~
회고
커버링 인덱스를 통해 조회 성능을 크게 향상시킬 수 있었다.
다만 아직 '인기 거래소 조회'가 2초대를 넘는데, 원인을 분석하고 좀 더 개선시켜보고, 인기 항목인 만큼 최후의 수단으로 캐싱도 고려해보자
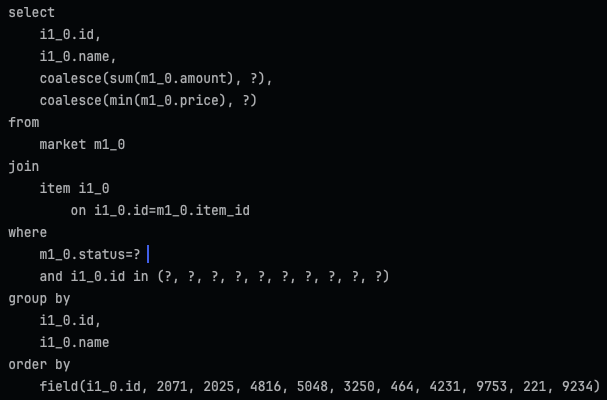
현재 짚이는 원인은 커버링 인덱스용 서브쿼리에서 join이 일어나는 것이다.
db구조상 auction은 bid와 1:1관계라 biddercount를 auction테이블에 두어 join이 일어나지 않아 인기 조회에서도 쉽게 성능을 개선시킬 수 있었지만,
market은 trade와 1:n 이고, item과 trade도 1:n이며, itemId별로 tradeCount 테이블이 따로 존재하는 바람에 생긴 문제다.
쿼리를 한 단계 더 나누어야 하나?
1. tradeCount desc인덱스를 두고 itemId를 추출
2. 추출한 itemId로 두번째 서브쿼리로 status, createdAt 등 정렬
3. 최종적으로 정렬된 itemId로 join실행
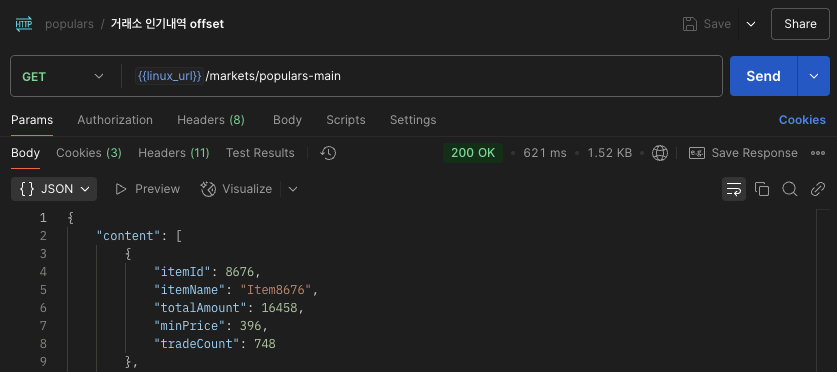
이게되네
역시 회고는 최고야
1. 인기 거래소 조회: 8.51s -> 621ms
1. PagableExecutionUtils + fetchCount로 조회되던 쿼리를, PageImpl + 고정값으로 변경: 8.51s -> 4.46s
2. Covering index 적용(Serve Query 분리): 4.46s -> 2.25s
3. Serve Query를 한번 더 분리하여 join 최적화: 2.25s -> 621ms
2. 전체 거래소 조회: 5.79s -> 333ms
1. PageableExecutionUtils + fetchCount로 조회되던 쿼리를, PageImpl + countQuery로 변경: 5.79s -> 4.98s
2. TotalCount에 들어가는 countQuery를 최적화: 4.98s -> 3.03s
3. Covering index 단순 적용: 3.03s -> 1.20s
4. Covering index용 Serve Query와 Main Query 분리: 1.20s -> 334ms
3. 인기 경매장 조회: 22.28s -> 322ms
1. PagableExecutionUtils + fetchCount로 조회되던 쿼리를, PageImpl + 고정값으로 변경: 22.28s -> 9.23s
2. Covering index 적용(Serve Query 분리): 9.23s -> 322ms
4. 전체 경매장 조회: 24.48s -> 702ms
1. PageableExecutionUtils + fetchCount로 조회되던 쿼리를, PageImpl + countQuery로 변경: 24.48s -> 10.47s
2. Covering index 적용(Serve Query 분리): 10.47s -> 702ms
참고!
https://jojoldu.tistory.com/476
1. 커버링 인덱스 (기본 지식 / WHERE / GROUP BY)
일반적으로 인덱스를 설계한다고하면 WHERE절에 대한 인덱스 설계를 이야기하지만 사실 WHERE뿐만 아니라 쿼리 전체에 대해 인덱스 설계가 필요합니다. 인덱스의 전반적인 내용은 이전 포스팅을
jojoldu.tistory.com
'팀 프로젝트 > market.normalization.project' 카테고리의 다른 글
| 조회 성능 향상시키기(3) Pagination Count Query 최적화 (0) | 2025.03.23 |
|---|---|
| 조회 성능 향상시키기(1) PageableExecutionUtils? (0) | 2025.03.21 |
| 플러스 프로젝트 KPT 회고 (0) | 2025.02.07 |


