
디스크 I/O와 인덱스
DB성능 튜닝에서 가장 신경써야 할 병목 중 하나는 디스크 I/O 이다. SSD가 HDD보다 수 배 이상 빠른 처리량을 보여주기 때문에, DB서버에는 주로 SSD를 사용한다.
디스크 I/O는 다시 랜덤 I/O와 순차 I/O로 나뉘는데,
순차 I/O:
디스크에서 연속된 위치를 읽는 경우, 한 번 헤더가 움직여서 쭉 읽으면 되니까 비교적 빠르다.
랜덤 I/O:
디스크 여러 곳을 이리저리 읽어야 해서, 매번 헤더를 옮겨야 하므로 비교적 느리다. DB쿼리가 랜덤 I/O를 많이 일으키면 속도가 크게 떨어진다.
(HDD에서는 둘의 차이가 크지만, SSD에서는 크지 않다.)
따라서 순차 I/O와 랜덤 I/O는 또 쿼리 튜닝의 포인트가 된다. 그런데 쿼리 튜닝으로 랜덤 I/O를 단순히 순차 I/O로 변경할 방법은 많지 않으므로, 랜덤 I/O를 최소화 하는 것을 목표로 두게 된다.
랜덤 I/O를 최소화 하는 것은 쿼리를 처리하는 데 꼭 필요한 데이터만 읽도록 쿼리를 개선(인덱스를 걸거나, SELECT문에 꼭 필요한 컬럼만 넣거나)하는 것이다.
인덱스 레인지 스캔은 랜덤 I/O를 야기한다.
인덱스는 B-Tree 구조로 되어 있어서, 검색할 때 여러 디스크 블록을 건너뛰어 접근한다.
그런데 어떻게 인덱스를 걸어서 랜덤 I/O를 줄이고 성능을 향상시킬 수 있을까?
1. 풀 테이블 스캔은 전체 블록을 쭉 읽는 순차 I/O 작업이지만, 그 데이터량이 매우 많으면 어차피 엄청난 I/O가 발생한다.
인덱스를 통해 필요한 레코드만 골라내면, 읽어야 하는 블록 수 자체가 적어져서 총 I/O 횟수가 크게 줄어든다. 비록 인덱스 레인지 스캔이 랜덤 I/O라 해도, 결과적으로 I/O가 감소하여 성능이 향상된다.
2. 쿼리에서 필요한 모든 컬럼을 인덱스에 포함해두면, 테이블 블록 접근 없이 인덱스만 보고 결과를 낼 수 있다(커버링 인덱스). 테이블 접근 자체를 생략하니 디스크 I/O가 줄어든다.
따라서 인덱스를 잘 걸면, 디스크 랜덤 I/O를 줄여 성능을 향상시킬 수 있다.
인덱스를 사용할 때 주의할 점 1: 스캔 방향
MySQL의 인덱스는 내부적으로 오름차순 정렬된 B-Tree 형태로 저장되는게 기본이다. (사용자가 설정하면 8.0이상부턴 DESC도 사용가능)
그리고 MySQL 옵티마이저는, "오름차순 인덱스를 역방향으로 읽는 게 낫겠다" 라거나 "내림차순 인덱스를 정방향으로 읽는 게 낫겠다" 등 상황 별로 최적의 경로를 고른다. 하지만 B-Tree를 역방향으로 타는 것 자체가 추가 비용이 있을 수 있다.
오름차순 인덱스에서 오름차순 방향으로 스캔하면 노드를 순서대로 따라가기만 하면 되니까 디스크 접근이 비교적 효율적이다.
하지만 인덱스를 반대 방향으로 읽으려면, B-Tree의 링크를 거꾸로 타고 가거나, 다음 노드로의 포인터를 역순으로 따라가야 한다.
이 과정에서 내부 포인터 탐색이 많아지고, 캐시 히트율이 떨어지거나 블록을 불규칙하게 읽게 될 가능성이 커져서 성능이 저하될 수 있다.
500만개 정도의 행을 가진 채용공고 더미데이터로 테스트를 해보자.

여러 번 수행 결과 큰 차이는 없지만 ASC(기본값)가 모든 결과에서 더 빠른 것을 볼 수 있었다.
인덱스를 사용할 때 주의할 점 2: 선택도
인덱스의 선택도(Selectivity)란, 모든 인덱스 키 값 가운데 유니크한 값의 수를 의미한다. 기수성(Cardinality) 또한 거의 같은 의미로 사용된다.
"선택도가 높다" => 인덱스 검색이 효율적이다
인덱스 검색 시 결과로 반환되는 레코드 수가 적을 때, 쿼리가 대상 행을 매우 좁은 범위로 한정한다. 테이블 전체를 읽지 않고 필요한 행만 찾아서 빠르게 랜덤I/O로 처리할 수 있다.
"선택도가 낮다" => 인덱스 검색이 비효율적이다
인덱스 검색 시 결과로 반환되는 레코드 수가 많을 때, 쿼리가 대부분의 데이터를 가져오게 된다.
이럴 때 MySQL 옵티마이저는 종종 인덱스 스캔보다 풀스캔을 택하게 된다. 인덱스 스캔을 수행했을 때 랜덤I/O 비용보다, 풀스캔 순차I/O비용이 더 저렴하기 때문이다.
인덱스를 사용할 때 주의할 점 3: 복합 인덱스
복합 인덱스는 순서가 중요하다. 예를 들어 (A, B)로 만든 인덱스를 사용할 때, 주로 A를 조건으로 검색해야 그 뒤에 B까지 인덱스를 효율적으로 사용할 수 있다. B만 단독으로 검색할 때는 그냥 풀스캔이 일어나는 경우가 생길 수 있다.

채용공고 더미데이터 500만개에 viewcount, salary 복합인덱스를 걸고,

세가지 실행 계획을 비교해보자.



첫번째, 두번째는 index를 이용했지만, 세번째 where절에서 salary만 비교한 쿼리는 인덱스를 사용하지 못해 풀테이블스캔이 일어난 것을 볼 수 있다.
이처럼 복합인덱스는 컬럼의 활용 패턴을 적절히 분석한 후 사용해야 한다.
인덱스를 사용할 때 주의할 점 4: 가용성
복합 인덱스의 오른쪽 값만을 사용할 수 없는 것 처럼, B-Tree 인덱스의 특성 상 또 인덱스를 아예 사용할 수 없는 경우가 있다.
1. NOT EQUAL

employment_type에 인덱스를 걸고 where equal 조건으로 검색하면 인덱스를 정상적으로 사용하지만,

not equal (!=) 일 경우 인덱스를 활용하지 못한다.
2. 와일드카드(%)의 위치

와일드카드가 뒤에 올 경우 possible_keys에 인덱스가 보이지만,
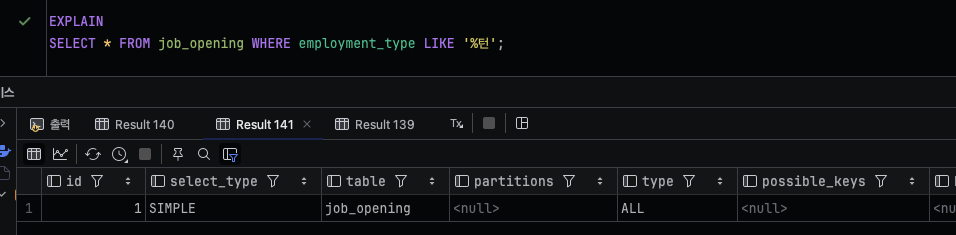
와일드카드가 앞에 올 경우 possible_keys가 null이다.
인덱스를 사용할 수 있음에도 ALL로 풀 스캔을 한 이유는 employment_type의 선택도가 낮기 때문이다.(지금 인턴과 정규직만 존재한다.)

title처럼 선택도가 높은 컬럼은 정상적으로 index range scan을 진행하게된다.
3. OR 절

OR조건이 걸린 컬럼 중 하나라도 인덱스를 사용하지 못하면, 풀 테이블 스캔을 수행할 가능성이 높다.
이 외에도 여러 경우가 존재한다.
마무리
인덱스를 잘 걸면 랜덤I/O를 줄여 성능을 향상시킬 수 있다.
하지만 인덱스는 데이터 삽입/수정/삭제 시 오버헤드를 불러일으키며, 오히려 풀테이블스캔을 유발해 느려지는 경우도 있으니 적재적소에 잘 사용하자.
'독서기록장' 카테고리의 다른 글
| 6. 운영체제 9장 메모리 (1) with redis.. (0) | 2025.03.28 |
|---|---|
| 4. 운영체제 4장 스레드 동기, 비동기, 스레드풀 (0) | 2025.02.10 |
| 3. 운영체제 3장 프로세스 간 통신 (0) | 2025.01.30 |



