
기존 방식의 문제점
@Slf4j
@Component
@RequiredArgsConstructor
public class SchedulerLockUtil {
private final RedisTemplate<String, String> redisTemplate;
private static final String LOCK_VALUE = InstanceUtil.getInstanceId();
/**
* 인스턴스 단위로 스케줄링을 관리하는 유틸메서드입니다.
* key 와 ttl 을 인자로 받아 redis 에서 관리합니다.
*/
public void lock(String keyName) {
//setIfAbsent 로 원자적으로 락을 잡으려 시도
Boolean acquired = redisTemplate
.opsForValue()
.setIfAbsent(keyName, LOCK_VALUE, 5, TimeUnit.MINUTES);
//락을 못 잡았다면 내 인스턴스의 락인지 확인
if (Boolean.FALSE.equals(acquired)) {
String currentValue = redisTemplate.opsForValue().get(keyName);
//다른 인스턴스의 소유라면 그냥 리턴
if (!LOCK_VALUE.equals(currentValue)) {
log.info("다른 인스턴스에서 실행중인 스케줄러입니다.");
throw new IllegalStatusException(ServerErrorCode.ALREADY_RUNNING_SCHEDULER);
}
//만약 내 인스턴스라면 이전 스케줄이 남긴 락이거나 ttl 이 안 끝난 상황일 수 있으므로 ttl 재갱신
redisTemplate.expire(keyName, 5, TimeUnit.MINUTES);
}
}
}다중 인스턴스 환경에서 동일한 스케줄러가 동시에 실행되지 않도록 하기 위해 기존에는 Redis 기반의 분산 락을 사용하고 있었다.
SchedulerLockUtil를 구현해서 특정 키(스케줄러 정보)를 기반으로 현재 실행중인 인스턴스(value에 인스턴스 고유id를 담아서) 현재 실행중인 인스턴스만 락을 유지하도록 구현하였다.
이렇게 다중 인스턴스 환경에서 스케줄러가 "중복 실행" 되지 않도록 유틸클래스를 구성해서,
어디에서든 재사용할 수 있도록 모든 스케줄러에 해당 로직을 사용해 중복 실행을 방지할 수 있었다.
원래 코드의 로직은 이러하다.
다른 인스턴스에서 락을 점유 중이면 예외를 발생시켜 중복을 막는다.
현재 인스턴스의 락이 존재한다면 TTL을 갱신해서 현재 인스턴스에서만 쭉 실행되도록 유지시킨다.
하지만, 여기서 새로운 문제가 발생하였다.
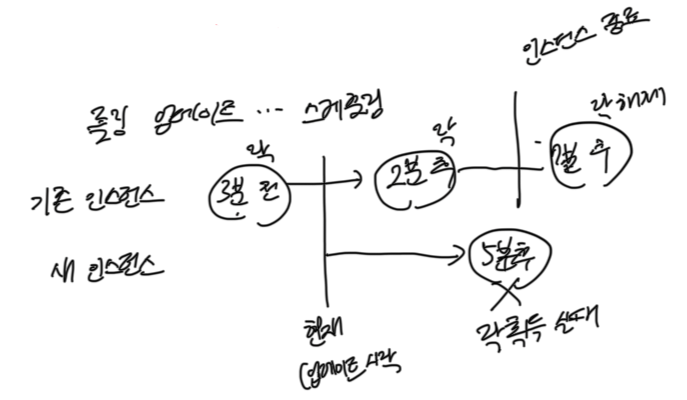
롤링 업데이트가 진행되면서 새로운 인스턴스가 올라올 경우에,
스케줄러의 중복 실행은 방지되지만 기존인스턴스에서 스케줄링이 실행되던 시점을 기억하게 할 순 없었고
그리하여 스케줄러 동작 타이밍이 꼬이는 문제가 발생했다.
이를 해결하려면 "스케줄링 실행 자체를 단일 인스턴스에 맡기는 방식" 이 필요했고,
각 인스턴스에서 직접 실행하지 말고, Redis에 작업을 등록해서 스케줄러 작업 실행을 중앙에서 제어하는 방식으로 전환할 필요성을 느꼈다.
애초에 스케줄링을 "단일 인스턴스가 보장되는" Redis에게 작업을 맡기면 되는 문제였다!
Redis를 활용한 해결책
Redis를 이용해 작업들을 큐에 넣고 하나의 인스턴스만 실행하는 구조로 변경하자!
1. 스케줄링 시간에 맞춰서 Redis에 작업을 등록한다.
2. Redis에서 오직 하나의, "가장 최신" 인스턴스만 작업을 소비하도록 처리한다.
최신 인스턴스만 작업하도록 설계되는 이유는, 롤링 업데이트 시 구버전 인스턴스에 작업을 할당했다간 해당 인스턴스가 terminate될 수 있기 때문이다.
3. 작업이 길어지든, 다중 인스턴스 환경에서든, 롤링 업데이트 시점이든 스케줄링 시간은 고정적으로 유지된다.
항상 "이전 실행시간" 과 어플리케이션에서 지정한 텀을 이용해 실행된다.
어플리케이션에서 스케줄링 시간을 짧은 주기로 항상 확인해야 하기에 i/o가 빠른 메모리 연산 기반의 Redis를 사용하였다.
아키텍처 개요

내가 구현한 것은 분산 작업 스케줄러로, Redis를 중앙 저장소로 사용해서 여러 인스턴스 간에 작업 중복 실행을 방지하고
분산 락과 큐를 통해 작업을 생산-소비 하는 구조다.
Redis에 "가장 최근에 실행된 작업 시간" 을 저장해두고, 각 인스턴스는 자신이 최신 인스턴스인지 확인한다.
최신 인스턴스가 아닌 경우에는 작업을 실행하지 않고, 최신 인스턴스만이 스케줄에 맞춰 작업을 수행한다.
어플리케이션이 시작될 때는 즉시 작업을 수행하며 첫 작업 실행 시간을 기록하게 되며,
해당 실행시간이 매번 업데이트되며 최초의 실행 시간에서부터 항상 같은 텀으로 이루어진다.
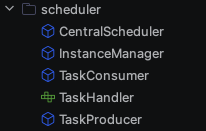
각각의 역할을 담당하는 컴포넌트가 서로 협력하면서 전체 작업 흐름을 관리한다.
CentralScheduler
주기적으로 작업 스케줄을 확인하고, 새 작업을 등록하는 책임을 가진다.

InstanceManager를 호출해서 현재 인스턴스가 최신 인스턴스인지 확인하고, 최신 인스턴스만 스케줄링을 진행하도록 한다.

각 작업 유형마다 Redis 분산 락을 사용해 중복 스케줄링을 방지한다(사실 우리 서비스에 데드락이 걸릴 정도로 텀이 짧은 스케줄링은 없지만 확장성을 생각해 설계했다). 락 획득 시간은 데드락 방지를 위해 적당히 스케줄링 간격의 절반으로 설정했다.
Redis에서 마지막(가장 최근의) 스케줄 시간을 읽어와서, 현재 시간이 지정된 스케줄 간격(마지막 스케줄 시간 + 작업 Term)을 넘었는지 체크한다.
조건을 만족하면 TaskProducer를 통해 작업을 등록하고 마지막 스케줄 시간을 업데이트한다.
InstanceManager
분산 환경에서 최신 인스턴스(리더)를 선출하는 책임을 가진다.

Redis에 저장된 최신 인스턴스 정보를 확인해서 현재 인스턴스가 최신인지 판단한다.
현재 인스턴스가 최신이라면 Redis에 최신 인스턴스로 등록한다.
TaskProducer
실제 작업을 등록하는 책임을 가진다. 새로운 작업을 생성해서 Redis의 Sorted Set에 추가한다.

작업 등록 시 고유 식별자와 작업 유행, 실행에 필요한 데이터(변수)를 포함하는 작업 객체를 생성하고, 작업 실행 시간을 score로 사용해 redis sorted set에 작업을 저장하여 시간에 맞춰 작업을 가져올 수 있게 설계하였다.
TaskConsumer
Redis Sorted Set에서 시간이 지난(실행 시점이 된) 작업을 가져와서 실행한다.

주기적으로 Redis Sorted Set을 폴링해와서 현재 시간보다 작거나 같은 score를 가진 작업들을 확인한다.

작업을 하나씩 꺼내서 json으로 파싱해 작업 유형에 맞는 taskHandler를 호출해 실제 작업을 처리한다.
TaskHandler
인터페이스로 정의되어 각 작업 타입 별 구체적인 처리 로직을 구현하도록 한다.

default로 정의된 두 개의 메서드가 작업 실행 term, payload를 관리한다.

payload의 경우에는 이런식으로 변수를 담도록 했다
실행 결과

도커로 인스턴스 두 개를 띄워서 테스트를 진행했다.

최초 실행 시, app이 app2보다 먼저 실행되어서 최신 인스턴스로 등록되며 스케줄링을 진행하였다.

app에서 스케줄링이 진행되는 동안, app2가 실행되었고

그 다음 스케줄링은 app2에서 진행된다!

DB에도 정상적으로 1분에 하나씩 데이터가 삽입된 걸 볼 수 있었다.
이렇게 분산 환경에서도 안전하게 스케줄링을 진행할 수 있게 되었다!
어플리케이션이 커지면 k8s에서 리더 선출이라는 걸 사용해볼 수 있다는데 비슷한 개념으로 진행되겠지?
이제 리팩토링을 해야겠다. -.- 지금 너무 redisson이랑 강하게 결합되어있다.
'팀 프로젝트 > cheerha.project' 카테고리의 다른 글
| 트러블슈팅: 크롤링 시 트랜잭션 범위가 너무 길다 (0) | 2025.03.08 |
|---|---|
| 크롤링 한 데이터를 어떻게 처리할까? (0) | 2025.03.05 |
| 채용공고 데이터를 크롤링해오자(3) 코틀린과 함수형 프로그래밍 리팩토링 (0) | 2025.03.04 |



