
요약

ec2 내부 한 컨테이너 안에 다 모아서 띄웠다

이제 서버 상태를 모니터링 할 수 있게 됐다
Prometheus + Grafana
지금 우리 팀이 만들고 있는 작은 프로젝트에서도 모니터링은 필수적이다.
메인 어플리케이션, mysql, redis 모두 단일 인스턴스로 운영중이므로 이 서버의 장애는 곧 전체 서비스의 마비를 뜻한다.
그렇기때문에 모니터링을 통해 제한된 리소스 내에서 효율적으로 서버를 운영해야 한다.
처음엔 aws cloudwatch로 모니터링을 시도했으나 요금이 부과되었고(..) 우리에게는 비용이라는 리소스마저 제한적이었다
그렇다고 매번 내부 서버까지 들어가서 로그를 찍어 볼 순 없으므로, "무료" "시각화" 툴이 필요했고 prometheus + grafana를 도입하게 되었다.
Prometheus와 Grafana는 모니터링을 위한 오픈소스 플랫폼이다. 재밌는 점은 이 툴을 SoundCloud에서 만들었다는거다
무료로 사용할 수 있고 거의 대체제가 없다. victoriametrics라는 훨씬 더 적은 리소스를 사용하는 오픈소스도 찾아볼 수 있었지만 국내자료가 너무 적어 초기 설정이 힘들 것 같아 제쳐뒀다
시계열 데이터베이스 기반(모든 데이터는 타임스탬프와 함께 저장된다)으로, 시간에 따라 연속적으로 생성되는 데이터를 처리할 때 효율적이다.
설치 과정
한개의 도커 컨테이너 내부에 때려박는 방법을 쓰면 아주 간단하다.
services:
app:
ports:
- "8080:8080"
networks:
- monitoring
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
networks:
- monitoring
depends_on:
- app
restart: always
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
networks:
- monitoring
depends_on:
- prometheus
restart: always
volumes:
- grafana-data:/var/lib/grafana
- grafana-config:/etc/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=비번
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
ports:
- "9100:9100"
networks:
- monitoring
restart: always
networks:
monitoring:
driver: bridgedocker-compose.yml 파일이다. 코드가 너무 길어져서 node-exporter(서버 전체의 cpu, ram 사용량 등을 prometheus에 export해주는 툴이다)만 들고왔다.
지금 한 인스턴스 안에서 실행하고 있기 때문에 서버를 껐다 킬 때 또는 배포(롤링업데이트)를 할 때 마다 grafana와 prometheus설정과 데이터가 초기화되기 때문에 볼륨 설정이 필수다
컴포즈파일을 이정도로 설정하고
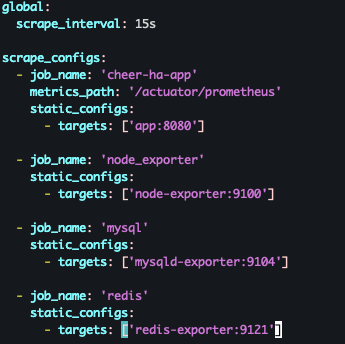
ec2내부에서 컴포즈파일과 같은 경로에 vi또는 nano로 prometheus.yml(프로메테우스 설정파일)을 만들어줘야한다
각각의 exporter들의 url을 프로메테우스에 인식시켜주는 파일이다
메인 app의 메트릭을 수집하려면 스프링부트 프로젝트 내에 actuator의존성이 필요하며
management:
endpoints:
web:
exposure:
include: health, prometheus
prometheus:
metrics:
export:
enabled: trueapplication.yml에 해당 설정을 통해 prometheus가 데이터를 수집할 수 있도록 열어놔야한다.
health는 로드밸런서에서 쓰는 헬스체킹용이라 무시해도된다
private static final String[] WHITE_LIST = {"/auth/signup", "/auth/login", "/actuator/health", "/actuator/prometheus"};어플리케이션 내부에서 필터를 사용한다면 whiteList 설정도 해줘야한다

해당 설정을 다 하고 ec2보안그룹을 열어주면 된다
3000번포트를 팀원들도 접근가능하게 팀원들의 ip를 받아와서 ip/32로 저장해주고,
프로메테우스는 나한테만 열어놨다(안 열어놔도 작동은 한다. 각각의 exporter들이 잘 연결되었나 확인하는 용으로 열어놨다)
이렇게 포트를 열어놓고, http://ec2ip:3000으로 들어가면 그라파나로 접속할 수 있다.
jvm&http 모니터링
그라파나 대시보드 id에 템플릿id 4701을 입력하면 spring boot actuator 메트릭들을 볼 수 있다.
커스텀해서 사용할 수도 있는데 아직 잘 모르니까 그냥 사용해보자

I/O Rate(http 요청 수):
갑자기 증가하면 트래픽 급증으로 인해 서버 부하가 발생할 수 있다.
또한 갑자기 감소한다면 서비스 장애나 네트워크 이슈가 생겼다는 뜻이다. 정상적인 운영 패턴을 파악하고,
비정상적인 급변이 있으면 원인을 분석해야 한다.
I/O Errors(http 5xx 응답 수):
500대 에러가 0이 아니라면 로그를 반드시 확인해야 한다.
지속적으로 발생한다면 서버 내부 오류, DB 연결 문제, 예외처리 미흡 등의 가능성이 있다.
CPU, RAM 사용량 증가 여부를 같이 체크해야 한다.
I/O Duration(http 응답 시간):
평균 응답 시간과 최대 응답 시간이 일정 수준을 넘어간다면 반드시 확인하고, 최적화해야한다.
응답 시간이 비정상적으로 증가한다면 CPU, GC 상태와 함께 분석해야한다.
JVM Heap Used:
jvm 힙 메모리 부족 가능성을 알려준다. 8-90% 이상이면 가비지컬렉터가 과부하 될 가능성이 있다.
지속적으로 증가하고 줄어들지 않으면 메모리 누수 가능성이 있다
JVM Non-Heap Used(Stack 아니고, 그 중간의 Metaspace 영역):
주로 클래스의 메타데이터, 코드 캐시 등을 포함한다.
너무 많이 사용된다면 Metaspace가 부족해 OutOfMemoryError 가능성이 있고,
증가 추세가 급격하다면 동적 클래스 로딩이 많거나 메모리 누수 가능성이 있다
[Java] 자바 메타스페이스(Metaspace)에 대해 알아보자.
Java Metaspace
jaemunbro.medium.com
jvm 외에도 여러가지 대시보드 템플릿이 존재하는데
7362: mysql(mysqld exporter) - 슬로우쿼리를 확인하고 최적화 할 수 있음, 트랜잭션 유지율, 테이블 락 등 확인하여 데드락 예상 가능
763: redis(redis exporter) - 메모리(메모리 기반이므로 매우 중요), 캐시 히트/미스율 등 확인 가능
1860: ec2(node exporter) - 서버 컴퓨터의 전체적인 상태 확인 가능
나중에 한번 각각 어떤 요소를 신중히 봐야하는지 정리해야겠다!
'팀 프로젝트 > 최종 프로젝트' 카테고리의 다른 글
| IP와 Email 차단을 DB로 옮기고 IP 전역 밴 추가하기 (0) | 2025.02.20 |
|---|---|
| Redis를 이용한 이상 사용자 차단 & 로깅 기능 구현 (0) | 2025.02.19 |
| 배포(완) RDS, ElastiCache 인프라 구축 (0) | 2025.02.17 |



