

해당 과제를 한 3가지 정도의 방법을 사용해보고 비교해볼것이다.
일단 찾아본 방법은
1. 비트리 인덱스
2. 해시 인덱스
3. 샤딩
full-text index는 사용하지 않기로 했다. 키워드 검색에는 괜찮은데 정확히 일치하는 검색에는 별로다
기본 like문부터 천천히 시작해보자!
기본 LIKE문 기반


일단 백만건의 데이터에게 혹사당할 오늘의 실험체 api이다
적절한 인덱스를 아직 만들지 않았기에 full table scan이 일어날 것으로 보인다
심지어 stream()을 이용해 데이터를 변환중이라 상당히 서버에 가혹한 api이다
@SpringBootTest
public class UserDataInsertTest {
@Autowired
private UserRepository userRepository;
@Commit
@Test
public void insertMillionUsers() {
int totalUsers = 1_000_000;
int batchSize = 10_000;
List<User> users = new ArrayList<>();
for (int i = 1; i <= totalUsers; i++) {
String randomEmail = "user" + i + "@example.com";
String randomNickname = "nick" + UUID.randomUUID().toString().substring(0, 8);
User user = new User(randomEmail, "password", UserRole.USER, randomNickname);
users.add(user);
if (i % batchSize == 0) {
userRepository.saveAll(users);
users.clear();
System.out.println("Inserted " + i);
}
}
// 남은 데이터 저장
if (!users.isEmpty()) {
userRepository.saveAll(users);
}
System.out.println("100만건 추가 완료");
}
}100만건의 데이터를 추가할 테스트코드다. 예~~~~~전에 한번 사용해봤던 UUID를 통해 닉네임을 생성해보기로 했다
검색 테스트 할땐 좀 불편할테지만 이만큼 랜덤인게 없긴하다.. 바로 100만건을 넣어보도록 하자.
처음에 @Transactional을 달았더니 테스트 이후에 롤백되어버려서..
해당 데이터가 테스트 종료 이후에도 롤백되지 않게 하기 위해 @Commit어노테이션을 사용했다.

추가 엄청 오래걸린당 호에엥..

왠진 모르겠는데 87만개에서 중지돼서 ㅠ users 와 nicks로 코드를 바꾸고 재실행해서 유저데이터가 100만개를 훨씬 넘겨버렸다 하하

170만개 럭키비키..
@Aspect
@Component
public class ExecutionTimeLoggingAspect {
private static final Logger logger = LoggerFactory.getLogger(ExecutionTimeLoggingAspect.class);
@Around("@annotation(org.example.expert.domain.common.annotation.LogExecutionTime)")
public Object logExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
Object proceed = joinPoint.proceed();
long executionTime = System.currentTimeMillis() - start;
logger.info("{} executed in {} ms", joinPoint.getSignature(), executionTime);
return proceed;
}
}로깅을 위한 어노테이션 aop도 추가해줬다. 실행시간을 측정하도록 설정했다
바로 like문 테스트를 돌려보자 ~.~!

서버 처음 실행시키고는 200ms정도

두번째 시도부터는 거의 120 정도 나오는 걸 보니 jpa에서 내부적으로 검색 결과 또는 검색과정이 캐싱되고있는듯했다.
캐싱 무시되게 설정할까했는데 솔직히 index쓰면 캐싱된 like문보다 빠를거같아서 그냥 스킵
나중에 좀 더 세밀하게 따져봐야겠다. 과연 어느 수준까지 접근하는지..
아무튼 LIKE문
200ms
B+Tree index 사용
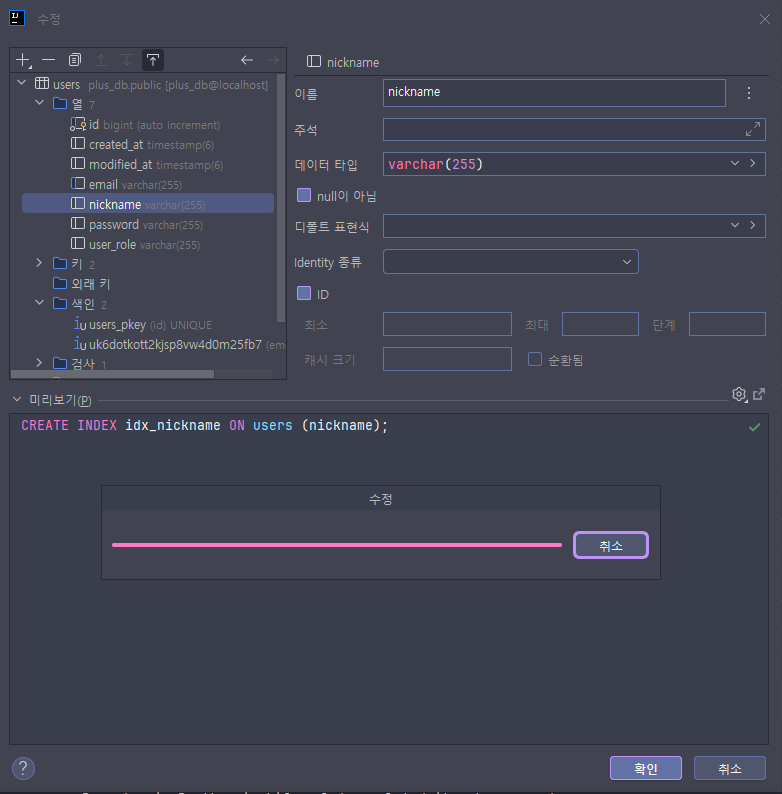
ide gui를 이용해서 닉네임에 인덱스를 추가해줬다. 비트리 인덱스의 경우에는, 내가 사용하는 postgresql에서는 간편하게 index를 추가하면 기본적으로 b+tree를 사용해서 편리하다는 장점이 있다.

idx_nickname이 추가됐당

첫 시도인데도 69ms.. 엄청나게 빠르다

2차 시도에서는 1ms걸렸다
이제 해시 인덱스, 샤딩을 사용해볼건데 얘들 로깅할때는 나노초도 추가해줘야겠다..ㅇㅅㅇ;
아무튼 B+Tree
69ms
'개인 공부용 프로젝트 > plus.project' 카테고리의 다른 글
| Lv.13 Hash index & Sharding (0) | 2025.01.17 |
|---|---|
| Lv.9 Spring security 도입하기 (0) | 2025.01.14 |

